
Although scheduling is only done by the scheduler we as DevOps always want to control that.
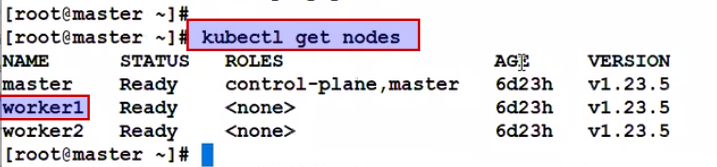
Suppose we have an application and the backend is working on one node. But I want them to be on different node:
- Node name Based
- Node label and selector
- Taint and toleration
- Affinity and anti-affinity based
Node name Based
Generally it is not recommended because We say this api should go to this worker node. Problem is because that node may be not fully highly available.
Practical :

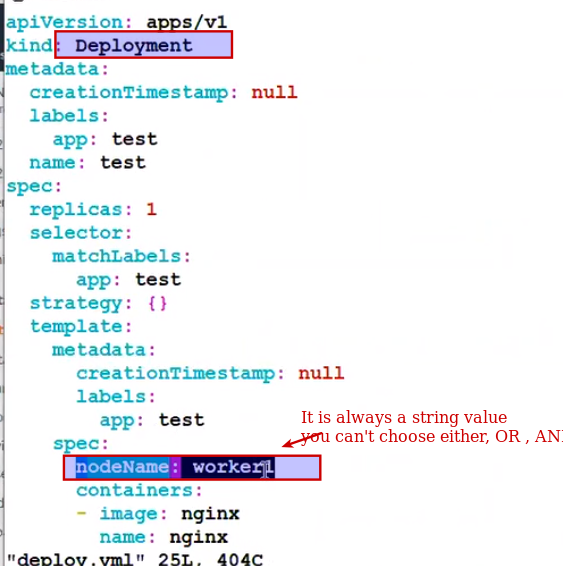
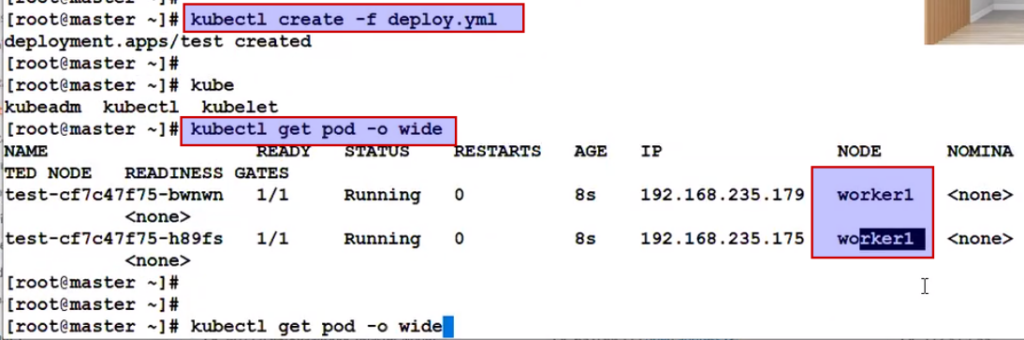
But suppose in one case , for any xyz reason your scheduling service is down and at the same time and your deployment came up. So will there be any scheduling happen for pod or not ?
Answer is yes, but only in case of node name based scheduling because this time your service is down but API already know where to schedule the pod, so it wll directly land you to that node inspite of scheduling service is running or not ?
But node label, selctor, taint, affinity , anti affinity only works if scheduling service is running.
###################
2) Node label and selector
Here it means there is one label to a node and that label will be a selector for pod. Means that pod will work on specific node
Node label1 and pod selector
Worker node jiska label label1 hai , and pod selector is same label label1 then all pod of having label label1 will go to workernode
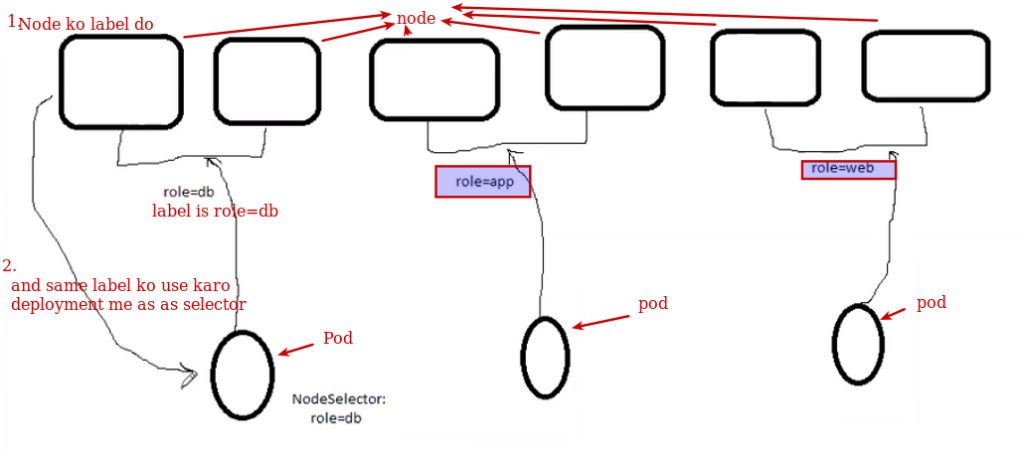
Now how to give label to node..
Same node ko mutilpe label we can give:
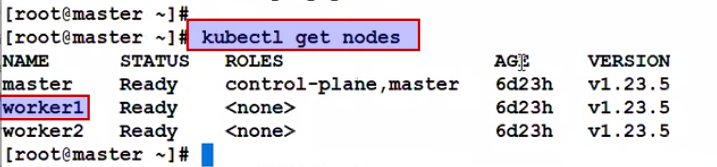
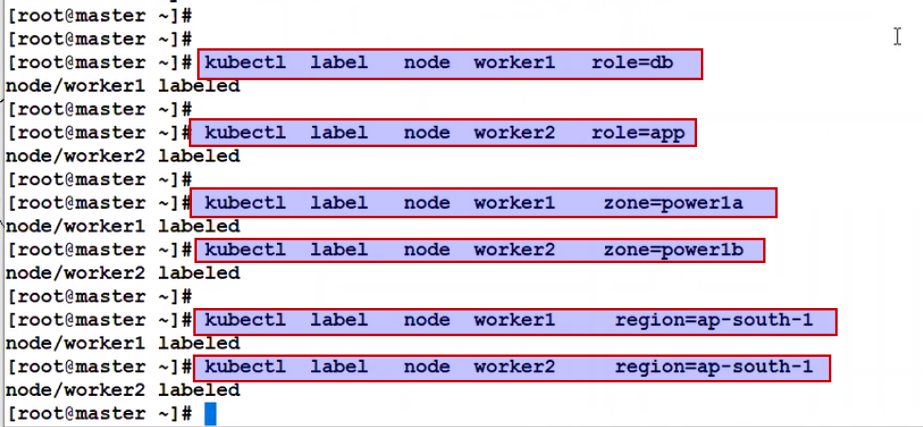

From kubectl edit command we can add and delete the label too.
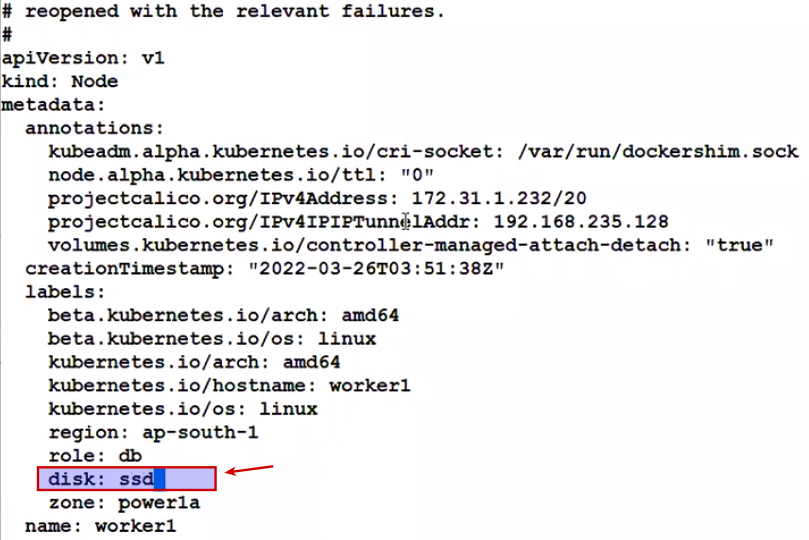
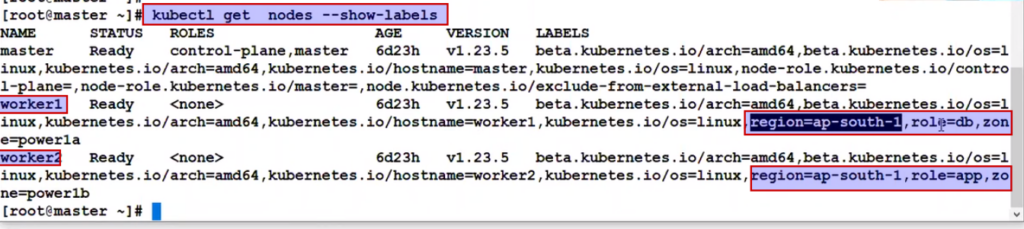
K8s gives by default some custom labels too..
Some different method:
Kubectl describe node worker1 | less
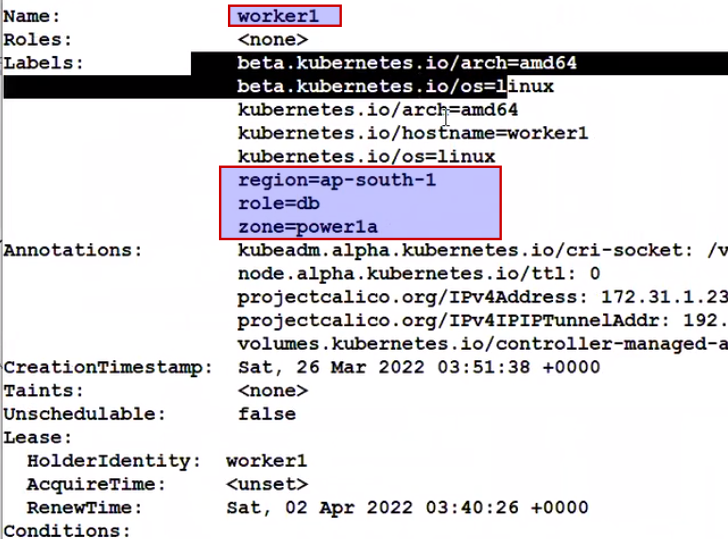
Good, now we will see how to use this label in deployment ?
Open your deployment.yml
Vim deploy.yml
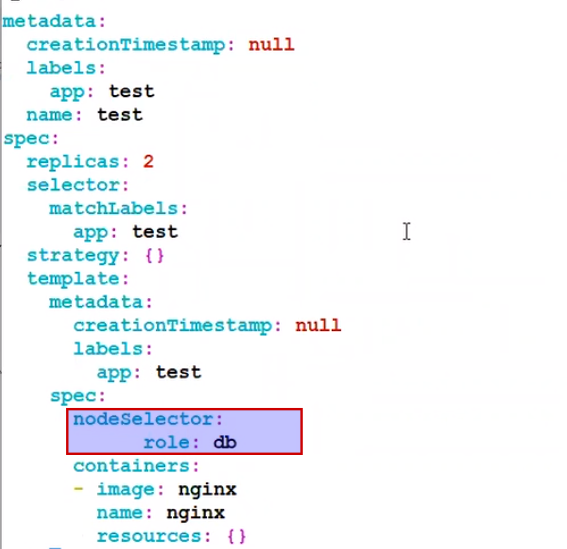
To apply two node selector in a deployment in Kubernetes, you can use the nodeSelector field in the deployment specification.
- Give label to worker node : k label node <node name> pod=bin-center-qa
- Give spec in deployment.
Here is an example of how to do it:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
spec:
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
nodeSelector:
node1: node1value
node2: node2value
containers:
- name: my-container
image: my-image
In this example, the nodeSelector field specifies that the pods created by this deployment should be scheduled on nodes that have the labels node1: node1value and node2: node2value. You can specify any label keys and values that match the labels on your nodes.
####
Suppose you have given wrong label which doesn't exist in any worker node.
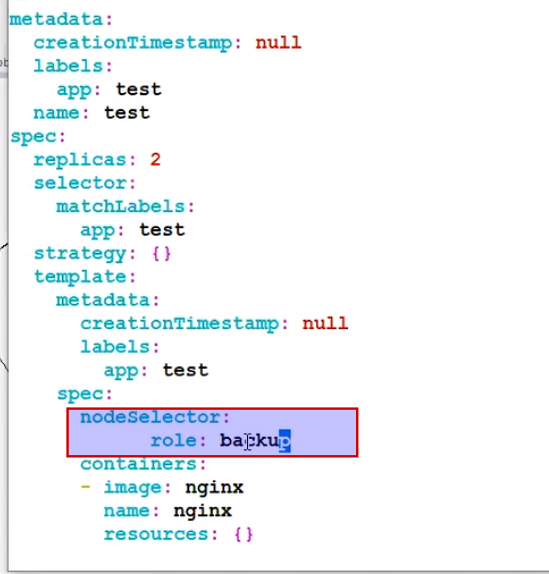
Deployment will create but pod will be in pending state.

There could be many reason for pod to be in pending state.
Scheduling rule not matching .
Kubectl describe pod

Kubectl edit deploy test

Change that
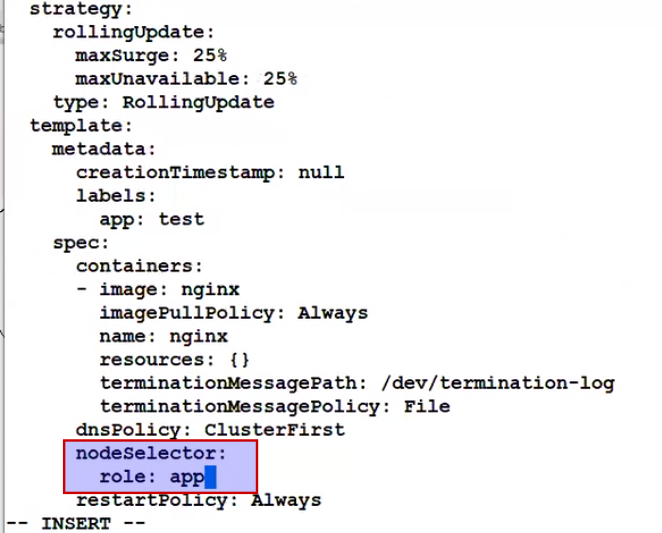

Once we save it and exit, we can see that older pod got delete and new pod got created.
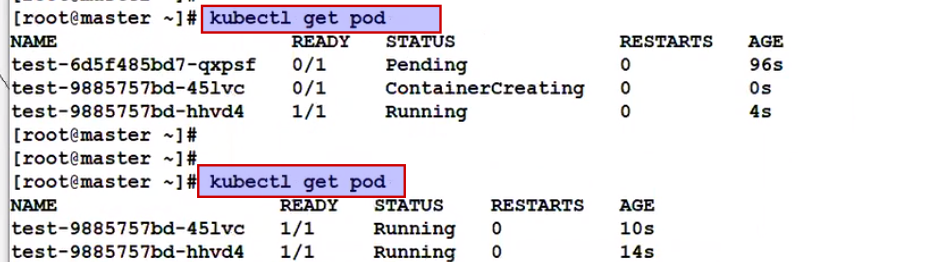

Now we have learnt so far every deployment we can add selector, but in one namespace we can have multiple deployment then ?
selector thing can be done at two level:
1) Deployment level
2) Namespace level
To do at the Namespace level we need to make a change at API config level.
K8s says my all container on control plane like api-server, scheduler , controller, etcd -->all manifest are also yaml based.
Kubelet load this manifest from /etc/kubernetes/manifest
It is written in kubelet that you need to pick from here.

Means all our container (api-server,scheduler, controller) create from below files.
API config parameter load from : /etc/kubernetes/manifest/

But don't go to api conainer and do the changes. All management happens from kube-apiserver.yml and understand like this file in mounted in container.

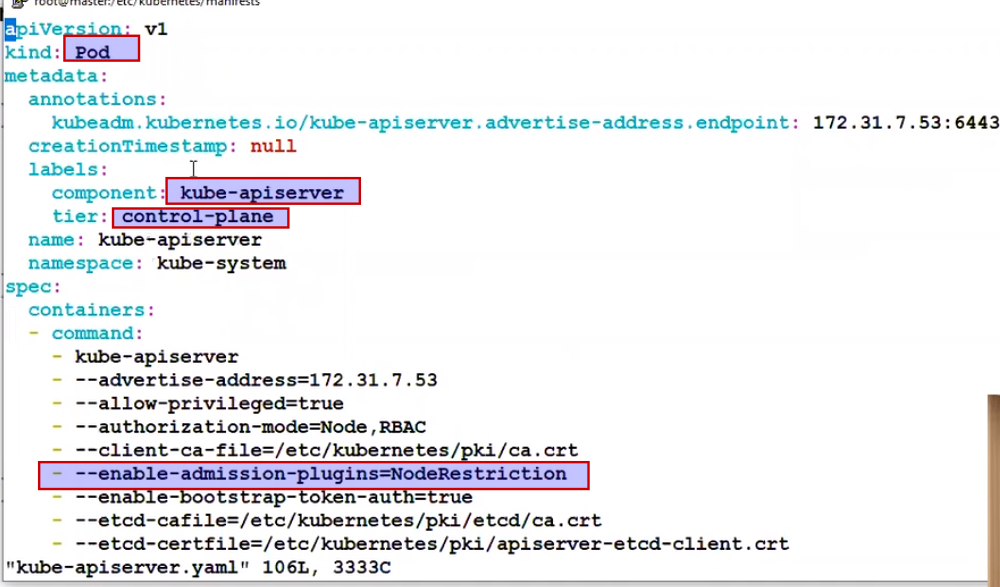
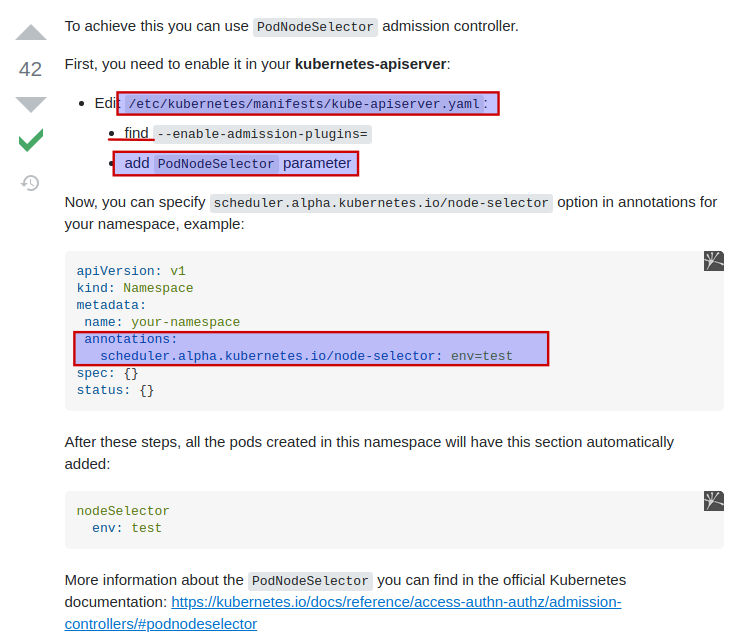
So now we have to enable node-selector feature from kube-apiserver.yaml
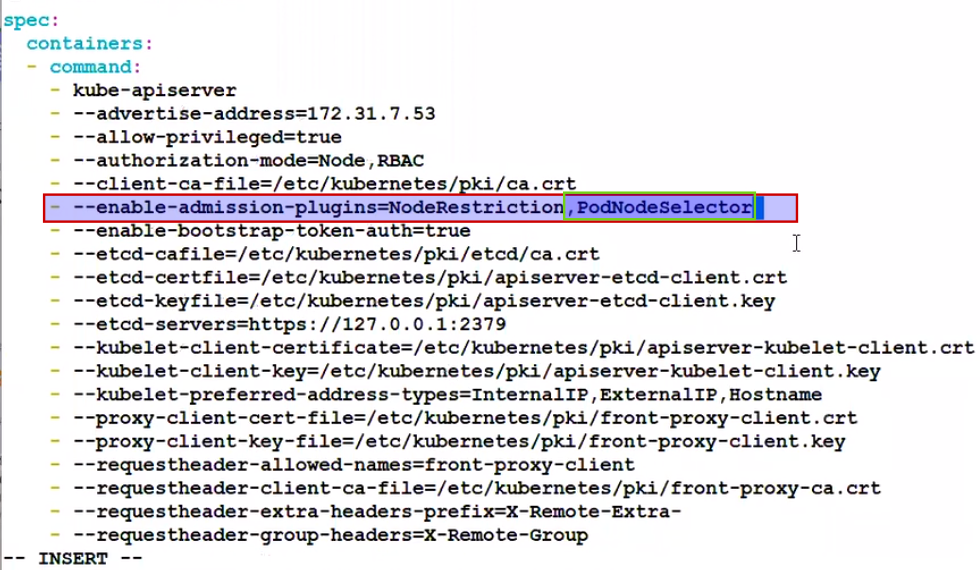
As soon as we save it , api-server will be down for 2 seconds
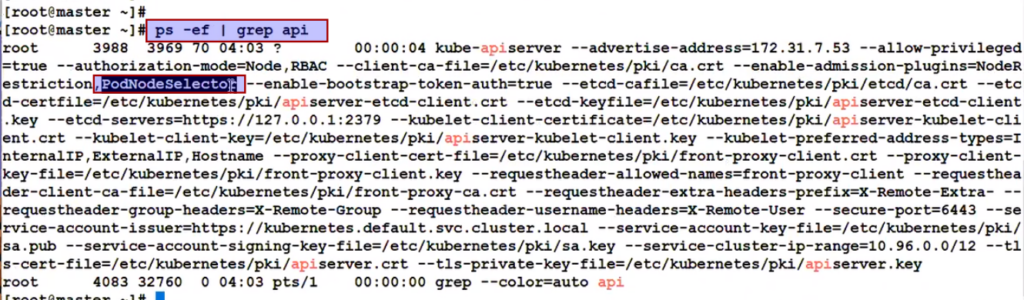
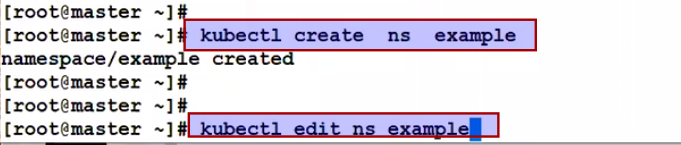
Now make the changes at the namespace level:


Reference Link:
https://kubernetes.io/docs/concepts/scheduling-eviction/pod-scheduling-readiness